博客内容Blog Content
大语言模型LLM概念入门理解 An Introductory Understanding of the Concept of Large Language Models (LLMs)
最近开始学习大语言模型LLM,本节介绍LLM和Transformer的概念、基本构建原理,以及搭建LLM的步骤 I recently started learning about large language models (LLMs). This section introduces the concepts of LLMs and Transformers, the basic principles of their construction, and the steps to build an LLM.
1.0 背景 Background
最近偶然发现了Sebastian Raschka先生的《Build a Large Language Model From Scratch》一书,没想读着读着发现挺有意思,该书思路不错,清晰地介绍了LLM的概念并描述了LLM的从0开始构建的过程和代码,我打算把一边学习一边把其核心内容按自己方式进行总结。
I recently came across Sebastian Raschka's book "Build a Large Language Model From Scratch". As I started reading it, I found it quite interesting. The book has a solid approach, clearly introducing the concept of large language models (LLMs) and describing the process and code for building an LLM from scratch. I plan to study it while summarizing its core content in my own way.

1.1 大模型概念 Concept of LLM
The “large” in “large language model” refers to both the model’s size in terms of parameters and the immense dataset on which it’s trained.
参数多、训练集大
1.2 大模型应用 LLM Application
Chatgpt、gemini、grok等问答机器人 Q&A Chatbot
知识库机器人 knowledge-based robots
无人技术 unmanned technology
1.3 大模型构建概念 Concepts of Building LLM
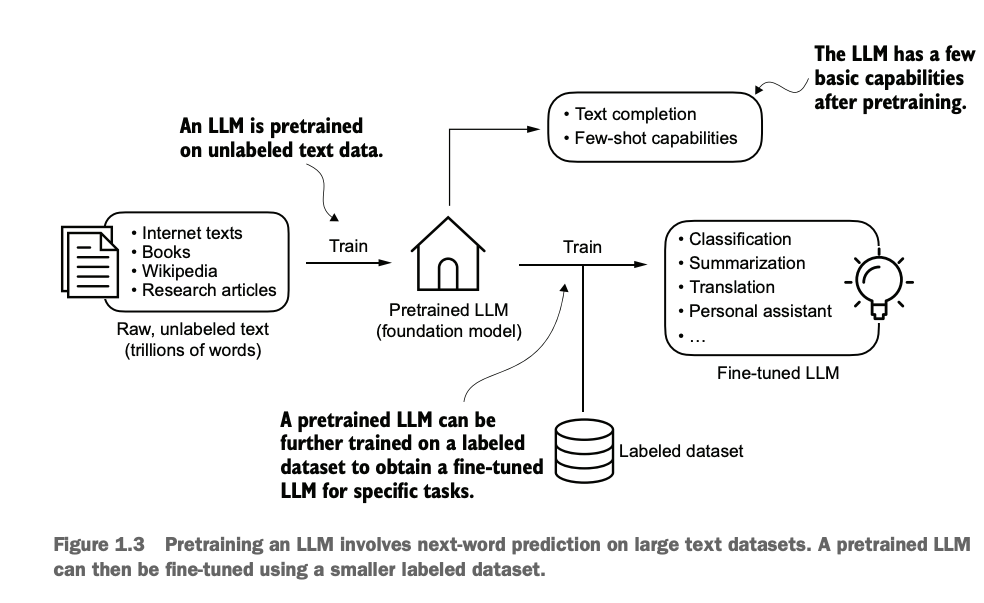
核心两步骤:预训练和微调
预训练:只需要无标签数据,训练出基本句子补全等基本能力,完成基模型foundation model
微调:使用foundation model加有标签数据做具体任务微调,可以微调成分类器或翻译器或bot等
Two Core Steps: Pretraining and Fine-tuning
Pretraining: Requires only unlabeled data to train the model for basic capabilities, such as sentence completion, resulting in a foundation model.
Fine-tuning: Uses the foundation model along with labeled data to fine-tune it for specific tasks, such as turning it into a classifier, translator, bot, etc.
自弄LLM好处:
领域微调的LLM模型能outperform通用模型,如BloombergGPT
数据不给第三方更安全
Benefits of Building Your Own LLM:
Domain-specific fine-tuned LLMs can outperform general-purpose models, such as BloombergGPT.
Data remains in-house, providing better security by not sharing it with third parties.
1.4 Transformer概念 Concept of Transformer
Decoder和Encoder
Encoder= eye & brain
Decoder= brain & mouth
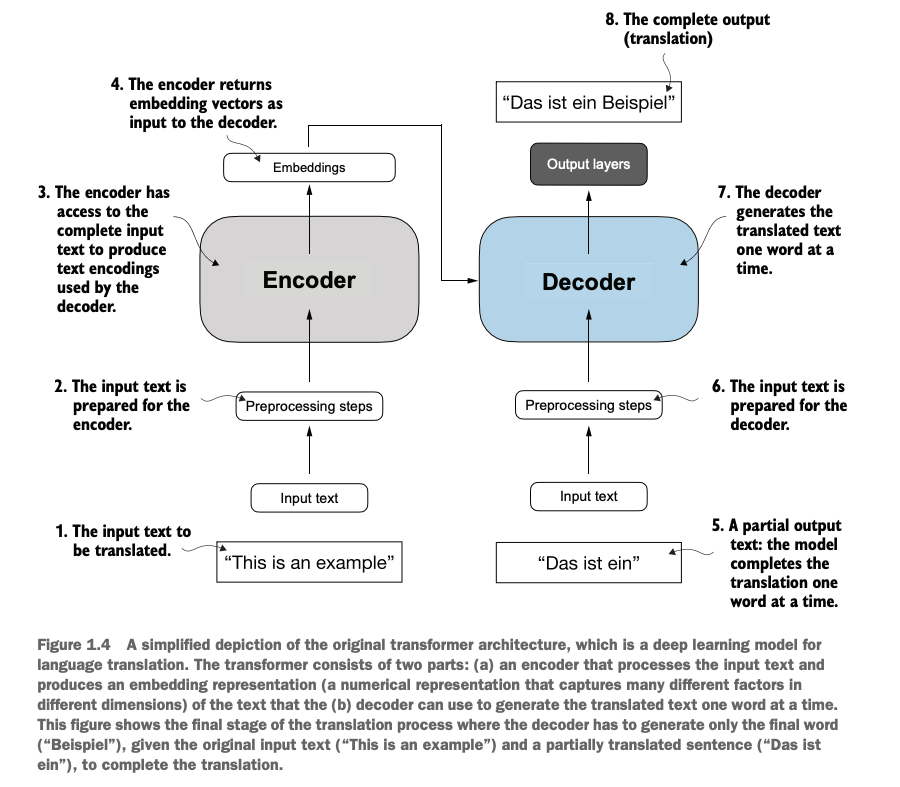

一个简单的语言翻译器:这个decoder利用了encoder输出的结果,和自己之前部分输出的中间结果,进行下一个词
A simpe language translator: This decoder utilizes the output from the encoder, along with part of its own previous outputs, to infer the next word.
BERT和GPT架构 Structure of BERT&GPT
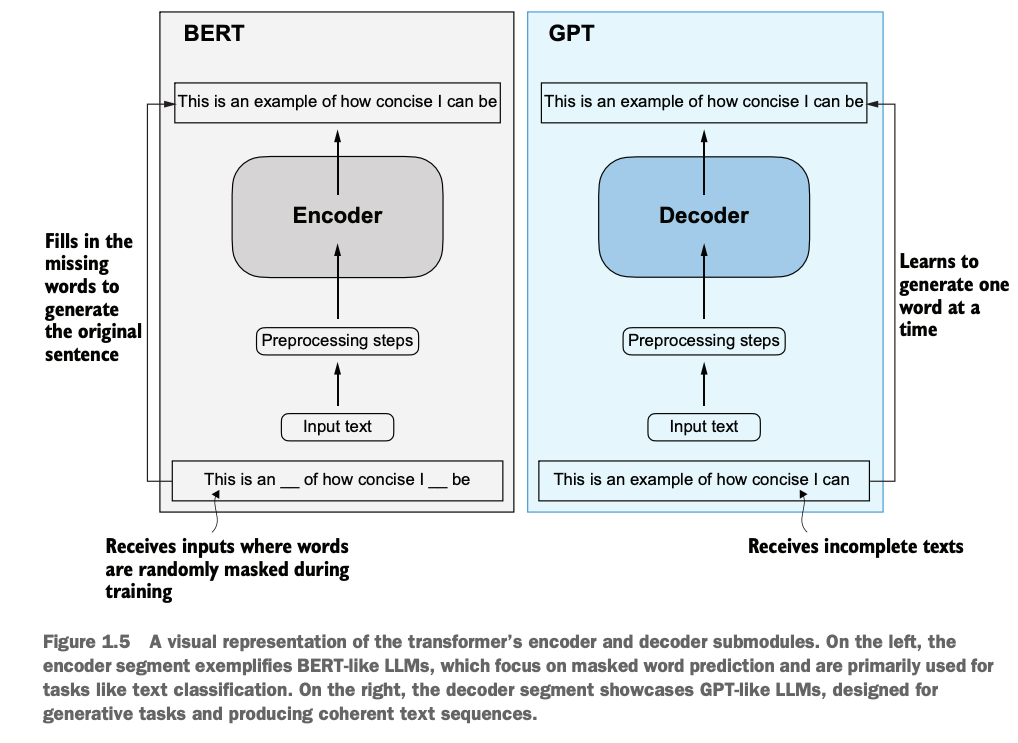
如图,BERT模型基于encoder构建,GPT模型基于Decoder构建
BERT用掩码语言建模(Masked Language Modeling,MLM),通过看全文双向预测隐藏的单词(完形填空)学习句子的整体语义。这种训练方法让 BERT 非常擅长理解整个句子的语义,因此它适合文本分类等需要整体理解的任务,比如情感分析、文档分类等。
GPT用自回归语言建模(Autoregressive Language Modeling),通过看前文单向生成新单词学习句子的自然表达方式。这种训练方法让 GPT 非常擅长生成自然语言,因此它适合生成任务,如文章生成、对话生成等。
As shown in the diagram, the BERT model is built on the encoder, while the GPT model is built on the decoder.
BERT uses Masked Language Modeling (MLM), learning the overall semantics of a sentence by predicting hidden words through bidirectional context by reading whole context (similar to fill-in-the-blank tasks). This training approach makes BERT highly effective at understanding the overall meaning of sentences, making it suitable for tasks that require comprehensive understanding, such as text classification, sentiment analysis, document classification, etc.
GPT uses Autoregressive Language Modeling, learning the natural expression of sentences by generating new words in a unidirectional manner by reading former context. This training approach makes GPT highly effective at generating natural language, making it suitable for generative tasks such as article generation, dialogue generation, and more.
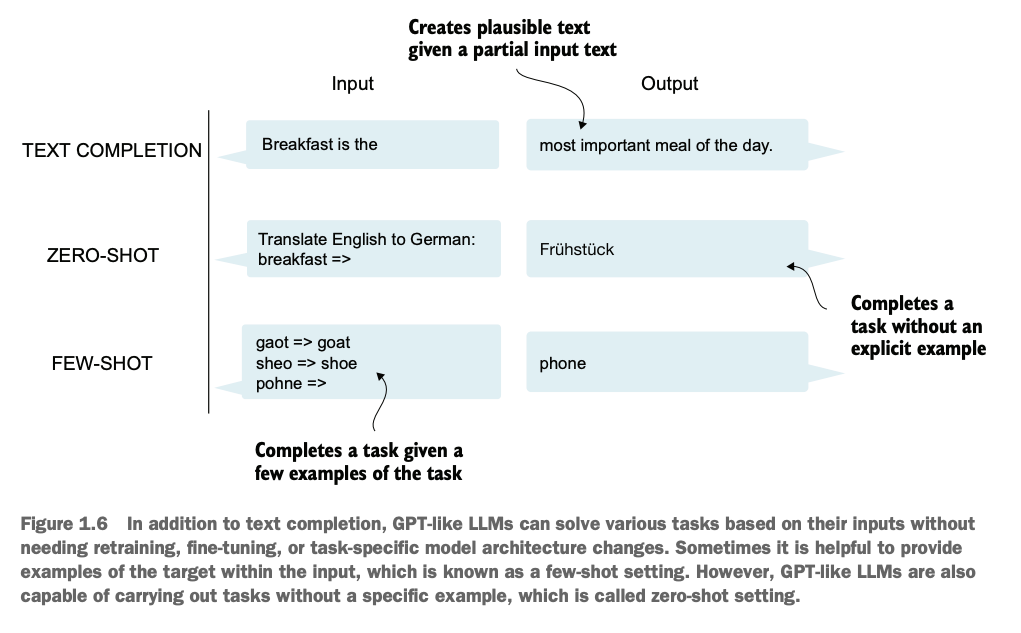
BERT is a bidirectional Transformer model using only the encoder. It is pretrained by masking parts of the input and learning to predict them, making it strong at understanding tasks like classification, question answering, and named entity recognition.
GPT is a unidirectional, decoder-only autoregressive model trained to predict the next word, which makes it excellent for generation tasks like writing, dialogue, and code generation.
BART combines the strengths of BERT and GPT with an encoder-decoder architecture. It is pretrained by corrupting input text and learning to reconstruct it, allowing it to perform well on both understanding and generation tasks such as summarization, translation, and question answering.
1.5 使用大数据集 Utilizing a large dataset
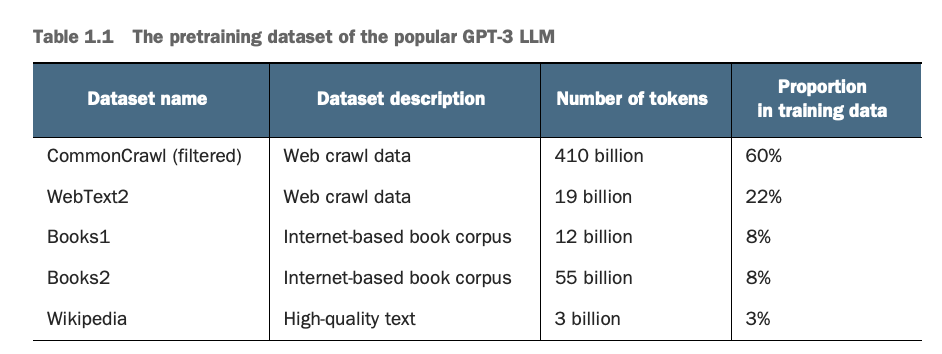
GPT3的训练集的多个来源的token数量和被分配的权重,较小但高质量的数据集(如 Wikipedia)可能会占据更高的比例
The number of tokens and assigned weights from various sources in GPT-3's training dataset show that smaller but higher-quality datasets (e.g., Wikipedia) may be given a higher proportion.
GPT训练的基模型很贵,在微调时很灵活,价值460万美元,但我们学习时可以使用开源免费的预训练的LLM基模型
Training GPT's foundational model is very expensive but highly flexible during fine-tuning. For example, GPT-3's base model cost $4.6 million to train. However, when learning, we can use open-source, pre-trained LLM foundation models for free.
1.6 GPT架构细节 Structures&Details of GPT
Self-supervised自监督模型:可用大量原始数据本身进行训练,不断预测下一个词
Autoregressive自回归:基于预测词的架构,把上一层的output当做input,通过对大规模语料进行训练,模型计算所有可能单词的概率分布,模型逐渐学会捕捉语言中的语法、语义和上下文关系。最终练就擅长生成的能力
Self-supervised Model: Trains using large amounts of raw data itself by continuously predicting the next word.
Autoregressive: A predictive architecture that uses the output of the previous layer as input. By training on large-scale corpora, the model calculates the probability distribution of all possible words, gradually learning to capture grammar, semantics, and contextual relationships in the language. This ultimately develops its strength in language generation.
架构极大,如Gpt3重复了encoder和decoder共6次,有96个transformer层和1750亿个参数
Massive Architecture: For instance, GPT-3 repeats the encoder and decoder structure six times, with 96 transformer layers and 175 billion parameters.
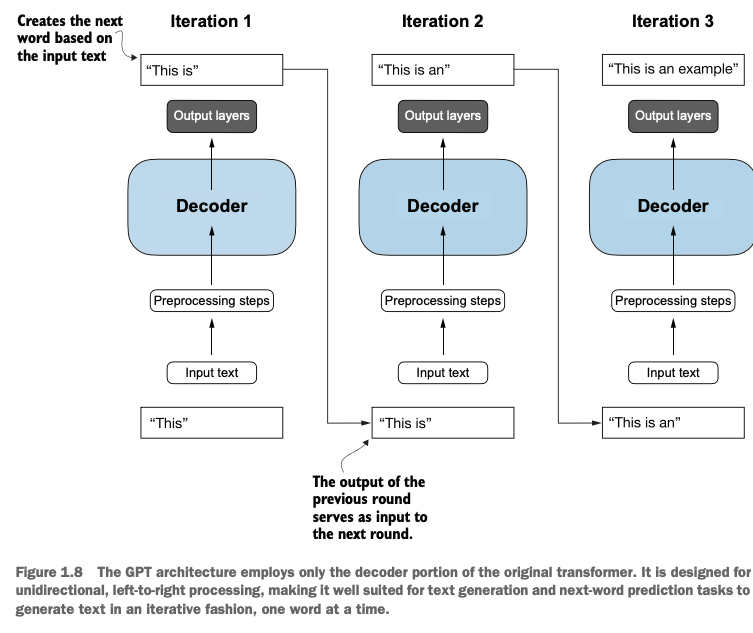
涌现行为(emergent behavior):GPT模型本来只用于预测下一个单词的,而非针对语言翻译设计,但其在接触了海量多语言数据和场景之后,也能够进行翻译任务了,变得有多用途
Emergent Behavior: The GPT model was originally designed only to predict the next word, not specifically for language translation. However, after being exposed to massive multilingual data and diverse scenarios, it developed the ability to perform translation tasks, becoming more versatile and multi-purpose.
1.7 构建LLM模型总体步骤 Overall Stages of Building LLM
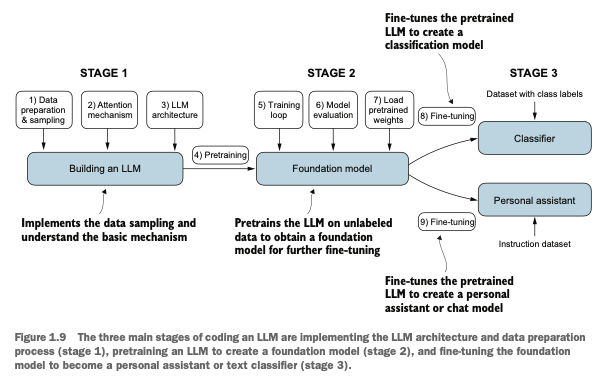
Stage1:数据处理、注意力机制、LLM核心架构准备
Stage2:预训练pretrain,生成能预测词的LLM,进行评估
Stage3:微调fine-tune训练的LLM,用于实际回答问题或者文本分类任务
Stage 1: Preparation of Data processing, attention mechanism, and the core architecture of LLM.
Stage 2: Pretraining to generate an LLM capable of predicting words, followed by evaluation.
Stage 3: Fine-tuning the trained LLM for practical tasks, such as answering questions or text classification.