博客内容Blog Content
基于Flink流计算实现的股票交易实时资产应用 The Applications of Realtime Stock Trading Based on Implementation of Flink Streaming
第四届实时计算Apache Flink挑战赛最佳实践奖 Best Practice Award in the 4th Real-Time Computing Apache Flink Challenge.
这是我的一篇被Apache开源社区微信公众号接受并发布技术分享文章
This is an article of my technical sharing, which has been accepted and published by the Apache open-source community WeChat official account.
微信链接Wechat Link:https://mp.weixin.qq.com/s/b4Hl6EUHBgrC5DH_nzMf8Q
阿里云链接Aliyun Link:https://developer.aliyun.com/article/1175318
参赛的附件和奖杯 Attachments and trophies from the competition

以下为原文:The following is the original text:

一、背景 Background
本次赛题思路源自于真实工作场景的一个线上项目,该项目在经过一系列优化后已稳定上线,在该项目开发的过程中数据平台组和技术负责人提供了许多资源和指导意见,而项目的结果也让我意识到了流计算在实际生产中优化的作用,进而加深了我对大数据应用的理解。
The idea for this competition topic originates from an online project in a real work scenario. After a series of optimizations, the project has been stably launched. During the development of this project, the data platform team and the technical lead provided many resources and guidance. The results of the project made me realize the role of stream processing in optimizing actual production, further deepening my understanding of big data applications.
1.1 成员简介 Member Introduction
陆冠兴:数据开发工程师,目前在互联网券商大数据部门工作,主要负责业务数据开发、数据平台建设、数据资产建设等相关工作,对流计算应用开发有一定经验。
Lu Guanxing: Data development engineer, currently working in the big data department of an internet brokerage. Primarily responsible for business data development, data platform construction, and data asset construction, with some experience in stream processing application development.
1.2 内容概述 Content Overview
本次赛题的主要内容,是通过引入流计算引擎 Flink+消息队列 Kafka,使用 ETL 模式取代原有架构的 ELT 模式计算出用户的实时资产,解决原有架构下计算和读取压力大的问题,实现存算分离;并以计算结果进一步做为数据源构建实时资产走势等数据应用,体现了更多的数据价值。
The main content of this competition topic involves introducing the stream processing engine Flink and the message queue Kafka, using an ETL (Extract, Transform, Load) model to replace the original ELT (Extract, Load, Transform) model to calculate users' real-time assets. This approach addresses the issues of high computation and read pressure under the original architecture and achieves the separation of storage and computation. Furthermore, the computed results are used as a data source to build data applications such as real-time asset trends, showcasing more data value.
1.3 一些概念 Some Concepts
在股票交易系统中,用户需要先进行开户得到一个账户,该账户包含账户现金和账户持仓两部分,之后就可以通过该账户进行流水操作,同时也可进交易操作。
流水 Transactions
出入金流水 = 往账户现金中存入/取出现金
出入货流水 = 往账户持仓中存入/取出股票
Cash Transactions: Deposits or withdrawals of cash into or from the account's cash balance.
Stock Transactions: Deposits or withdrawals of stocks into or from the account's holdings.
交易 Trading
买入股票 = 现金减少,股票持仓增加
卖出股票 = 现金增加,股票持仓减少
Buying Stocks: Decreases cash, increases stock holdings.
Selling Stocks: Increases cash, decreases stock holdings.
总资产的计算 Total Asset Calculation
用户总资产=账户现金+账户持仓股票市值
账户持仓股票市值 = 所持仓股票数量 * 对应的最新报价(实时变化)
User's Total Assets: Account cash + Market value of account stock holdings.
Market Value of Account Stock Holdings: Number of stocks held * Latest stock price (which changes in real-time).

1.4 传统架构的实现&痛点 Implementation & Pain Points of Traditional Architecture

当使用传统业务架构处理一个总资产的查询接口时,大致需要经过的步骤如下:
用户从客户端发起资产请求到后端
后端进程去业务 DB 里查询所有用户现金表、用户持仓股票表以及最新股票报价表数据
后端进程根据查询到的数据计算出用户持仓的市值,加上用户现金得到出用户最新总资产
将算出的总资产结果返回客户端展示
但随着请求量的增加,在该架构下数据库和计算性能都会很快达到瓶颈,主要原因是上面的第 2 步和第 3 步的计算流程较长并且未得到复用:
每次客户端的请求到来时,后端进程都需要向业务的 DB 发起多个查询请求去查询表,这个对于数据库是有一定压力
查询得到的数据库数据还需要计算才能得到结果,并且每来一个请求触发计算一次,这样的话 CPU 开销很大
When using a traditional business architecture to handle a total asset query interface, the process generally involves the following steps:
The user initiates an asset request from the client to the backend.
The backend process queries the business database (DB) for all data in the user cash table, user stock holdings table, and the latest stock price table.
The backend process computes the market value of the user's stock holdings based on the queried data, adds the user's cash balance, and then derives the user's latest total assets.
The computed total asset result is returned to the client for display.
However, as the volume of requests increases, the database and computation performance under this architecture quickly reach a bottleneck. The main reasons are the lengthy and non-reusable computation processes in steps 2 and 3:
Every time a request comes from the client, the backend process needs to issue multiple query requests to the business DB to retrieve data from the tables, which puts considerable pressure on the database.
The data retrieved from the database still needs to be computed to obtain the result, and each request triggers the computation separately, resulting in significant CPU overhead.
二、技术方案 Technical Solution
2.1 ETL 的架构&流计算 ETL Architecture & Stream Processing

这里一个更合理的架构方案是使用 ETL 的架构对此做优化。
A more reasonable architecture solution here is to optimize this using an ETL architecture.
对于 ELT 架构,主要体现在 T(转换)的这个环节的顺序上,ELT 是最后再做转换,而 ETL 是先做转换它的优点是因为先做了转换,能够方便下游直接复用计算的结果。
In the case of an ELT (Extract, Load, Transform) architecture, the main difference lies in the order of the T (Transform) step. ELT performs the transformation last, while ETL (Extract, Transform, Load) performs the transformation first. The advantage of ETL is that by performing the transformation upfront, the results can be easily reused by downstream processes.
那么回到总资产计算的这个例子,因为它的基本计算逻辑确定,而下游又有大量的查询需求,因此这个场景下适合把 T 前置,也就是采用 ETL 的架构。Returning to the example of total asset calculation, since its basic calculation logic is fixed and there is a high demand for queries downstream, this scenario is well-suited to move the T step forward, i.e., adopting an ETL architecture.

在使用 ETL 架构的同时,这里选择了 Flink 作为流计算引擎,因为 Flink 能带来如下好处:
仅在对应上游数据源有变更时触发算出对应的计算,避免了像批计算每个批次都需要去拉取全量数据源的开销
由于是事件触发计算最新的结果,所以实时性会比批计算会好很多
While using the ETL architecture, Flink was chosen as the stream processing engine because it offers the following benefits:
Calculations are triggered only when there are changes in the corresponding upstream data sources, avoiding the overhead of pulling the entire data source as required in batch processing for each batch.
Since the latest results are computed based on event triggers, the real-time performance is significantly better than batch processing.

那么新的架构实现可以大致如图,首先这里图中右边部分,通过引入 Flink 可先把计算的结果写到中间的数据仓库中;再把这个已算好数据提供给图中左边接口进行一个查询,并且因为数据仓库里面已经是算好的结果,所以接口几乎可以直接读取里面的数据无需再处理。
The new architecture can be roughly illustrated as follows:
First, in the right part of the diagram, by introducing Flink, the computed results can be written into an intermediate data warehouse. Then, the precomputed data is provided to the interface on the left side of the diagram for querying. Since the data in the warehouse is already precomputed, the interface can almost directly read the data without further processing.
2.2 架构实现 Architecture Implementation

实现这里主要分为三部分:数据接入、数据 ETL、提供数据。
The implementation is mainly divided into three parts: data ingestion, data ETL, and data provisioning.
2.2.1 数据接入 Data Ingestion
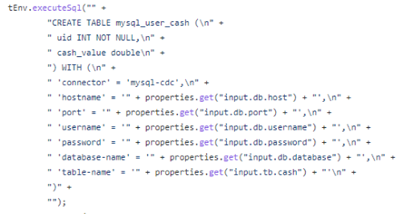
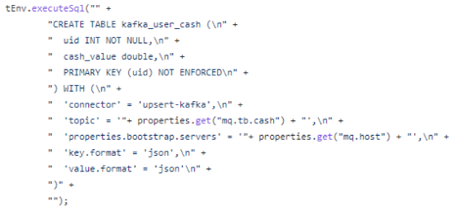
出于性能和 SQL 化的能力以及对 Flink 的兼容性考虑,这里主要使用的接入方案是 Flink CDC,整个 SQL 部分只需要确定数据源实例和库表的一些信息,以及要接入到的目标数据仓库信息,我们可在代码中 create 对应的 SQL,然后执行 insert 便可以完成整个接入。
For considerations of performance, SQL capabilities, and compatibility with Flink, Flink CDC is primarily used as the data ingestion solution here. The SQL part only requires specifying some information about the data source instances and database tables, as well as the target data warehouse information for ingestion. We can create the corresponding SQL in the code and then execute an INSERT to complete the entire ingestion process.
一个从业务 MySQL 数据库接入数仓 Kafka 消息队列的 demo 代码如下:
Here is a demo code snippet for ingesting data from a business MySQL database into a Kafka message queue in the data warehouse:

2.2.2 数据 ETL Data ETL
在数据完成接入后,我们就可以开始业务逻辑,也就是用户总资产的计算了。
Once the data ingestion is completed, we can start implementing the business logic, which in this case is the calculation of the user's total assets.
根据前面提到的计算公式,需要先对“账户持仓数据”和“股票报价数据”做一个关联,然后进行一次账户维度的聚合算出用户持仓市值,再和“账户现金数据”关联算出总资产,对应的 SQL 代码如下:
According to the calculation formula mentioned earlier, we first need to join the "account holdings data" with the "stock price data." Then, we perform an aggregation at the account level to calculate the market value of the user's holdings. Finally, we join this result with the "account cash data" to compute the total assets. The corresponding SQL code is as follows:


然而,在实际的运行中我们发现,数据的输出结果似乎很不稳定,变动频繁,输出的数据量很大,这里通过之前社区一些 Flink 的分享[1] 发现,这类实时流数据的 regular join 可能会有数据量放大和不准确的问题,原因是因为 Flink 有时会把上游的一条数据拆成两条数据(一条回撤,一条新值),然后再发给下游。
However, during actual operation, we found that the output data seemed very unstable, frequently fluctuating, and the volume of output data was quite large. From previous Flink community shares [1], we discovered that regular joins in real-time stream data might lead to data amplification and accuracy issues. The reason is that Flink sometimes splits an upstream record into two downstream records (one for retraction, one for the new value) before sending them downstream.
那在到我们总资产计算的这个场景中,可以看到在我们的 SQL,确实在关联之前和关联之后都会往下游输出数据;另外,再做聚合 SUM 的时候,上游的一个变化也可能触发两个不同的 SUM 结果;这些计算中间结果,都在不断地往下游输出,导致下游的数据量和数据的稳定性出现了一定的问题,因此这里要对这些回撤进行一个定的优化。
In the context of our total asset calculation scenario, we can see that in our SQL, data is indeed being output downstream both before and after the join. Additionally, when performing the SUM aggregation, a single change upstream might trigger two different SUM results. These intermediate computation results are continuously being sent downstream, which causes issues with the volume and stability of the downstream data. Therefore, it is necessary to optimize these retractions to improve the situation.

根据之前一些社区的分享经验来看,这里对应的一个解决方案是开启 mini-batch;原理上使用 mini-batch 是为了实现一个攒批,在同一个批次中把相同 KEY 的回撤数据做一个抵消,从而减少对下游的影响;所以这边里可以按照官方的文档做了对应的一个配置,那么数据量和稳定性的问题也就得到了初步的一个缓解。
Based on previous experiences shared within the community, a corresponding solution here is to enable mini-batch processing. The principle behind using mini-batch is to accumulate records within a single batch and offset the retraction records for the same key within that batch, thereby reducing the impact on downstream processes. By following the official documentation to configure this, the issues with data volume and stability can be initially alleviated.

2.2.3 提供数据 Data Provisioning
这部分的主要目的是将 ETL 计算好的结果进行保存,便于下游接口直接查询或者再做进一步的流计算使用,因此一般可以选择存储到数据库和消息队列中;
The main purpose of this part is to store the results calculated by the ETL process, making it convenient for downstream interfaces to directly query the data or use it for further stream processing. Therefore, the results are typically stored in a database or a message queue.

2.3 扩展数据应用 Expanding Data Applications
在完成基本数据模块的计算后,我们可以从数据的价值角度出发并探索更多可能,例如对已经接入的数据,可以再做一个二次的数据开发或挖掘,这样就可得到其它视角的数据,并进一步实现数据中台独特的价值。
After completing the basic data module calculations, we can explore more possibilities from the perspective of data value. For instance, the ingested data can undergo secondary development or mining, allowing us to derive data from other perspectives and further realize the unique value of a data middle platform.
以用户总资产为例,在我们在计算出用户总资产这个数据之后,我们可以再以此作为数据源,从而实现用户的实时总资产走势。
Taking the user's total assets as an example: after calculating the user's total assets, we can use this as a data source to achieve a real-time trend analysis of the user's total assets.

使用 Flink 自带的状态管理和算子的定时功能,我们可以大致按如下步骤进行实现:
接收上游不断更新的全量用户资产数据,并在 Flink 内部不断维护最新的用户资产截面
配置定时器,定期地扫描最新的用户资产截面,配上系统设定的时间戳,得到当前截面的资产快照数据
将当前截面的资产快照数据输出到下游的数据库或消息队列中
Using Flink's built-in state management and operator timer functionality, we can roughly implement the following steps:
Receive the continuously updated full user asset data from upstream and continuously maintain the latest user asset snapshot within Flink.
Configure a timer that periodically scans the latest user asset snapshot and, along with the system's configured timestamp, produces the asset snapshot data for the current moment.
Output the asset snapshot data for the current moment to a downstream database or message queue.

2.4 数据稳定性的挑战 Challenges to Data Stability
在项目实际上线过程中,我们还遇到了一些引入流计算后带来的挑战,有时这些问题会对数据的准确性和稳定性造成一定影响,其中首当其冲的是 DB 事务给 CDC 带来的困扰,尤其是业务 DB 的一个大事务,会在短时间内对表的数据带来比较大的冲击。
During the actual project launch, we encountered several challenges brought on by the introduction of stream processing. These issues sometimes impacted data accuracy and stability. A primary concern was the complications that database (DB) transactions caused for Change Data Capture (CDC). Particularly, a large transaction in the business DB could cause significant and sudden changes to the data in a table within a short period.

如图,假如业务 DB 出现了一个交易的大事务,会同时修改现金表和持仓表的数据,但下游处理过程是分开并且解耦的,而且各自处理的过程也不一致,就有可能出现钱货数据变动不同步的情况,那么在此期间算出的总资产就是不准确的。
As illustrated, if the business DB undergoes a large transaction, it might simultaneously modify the data in both the cash table and the holdings table. Since the downstream processing is decoupled and handled separately, and the processes for each are not synchronized, this could lead to inconsistencies where changes in cash and holdings data are not synchronized. Consequently, the total assets calculated during this period may be inaccurate.
那么这里针对这种情况,我们也有一些应对方案:首先一个方案和前面处理回撤流的思路类似,是通过窗口进行攒批次的一个处理,尤其是 session 窗口比较适合这个场景。
To address this situation, we have several strategies. One approach, similar to the method used for handling retraction streams, is to batch process the data using a window, with session windows being particularly suitable for this scenario.
例如下图中的代码,在计算出用户资产之后不是立刻输出结果,而是先做一个 session 窗口,把流之间最大可能延迟的变动包含进去,即把 session 窗口里面最新的结果作为一个比较稳定的结果作为输出;当然这里的 gap 不能太长,太长的话窗口可能会一直无法截断输出,需要根据实际情况选择合适的 gap 大小。
For example, in the code snippet below, after calculating the user's assets, the result is not immediately output. Instead, a session window is applied, which includes the maximum possible delay in changes between the streams. The latest result within the session window is then output as a more stable result. Of course, the gap in the session window should not be too long; if it's too long, the window might never close and thus never produce an output. The appropriate gap size should be chosen based on the actual scenario.

另一个方案的话可以是对此类大事务做一个识别,当上游触发一个很大的变动时,可以给 ETL 程序做一个提醒或预警感知,这样的话 ETL 程序就可以对输出数据做一个暂时的屏蔽,等到数据稳定之后再恢复输出。
Another approach could involve detecting such large transactions. When a significant change is triggered upstream, you can implement an alert or notification mechanism for the ETL process. This way, the ETL program can temporarily suppress the output of data and only resume output once the data has stabilized.
再有的话就可以是提升性能和算力,假设处理数据的机器性能越强,那在同样时间数据被处理就越会更快,各流之间的延迟就越小。
Additionally, improving performance and computational power is another viable strategy. If the machines processing the data are more powerful, the data will be processed faster within the same timeframe, thereby reducing the latency between streams. This, in turn, minimizes the likelihood of inconsistencies between different data streams.
三、总结 Summary

在这个场景中,我们通过引入 ETL 模式和 Flink 流计算引擎,实现了计算和存储的分离,将计算的负担从后端程序转移到了 Flink 流计算引擎上,方便的实现算力的动态扩缩容,还减少了对业务数据库读取的压力。除此之外,流计算出的实时结果还可以进一步给下游(用户实时走势)使用,实现了更多的数据应用价值。
In this scenario, by introducing the ETL model and the Flink stream processing engine, we achieved a separation of computation and storage. The computational load was shifted from the backend program to the Flink stream processing engine, which conveniently allows for dynamic scaling of compute resources. This also alleviated the pressure on the business database by reducing read operations. Moreover, the real-time results produced by stream processing can be further utilized by downstream processes (such as tracking users’ real-time trends), thereby realizing additional data application value.